Andy K. Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, et al.
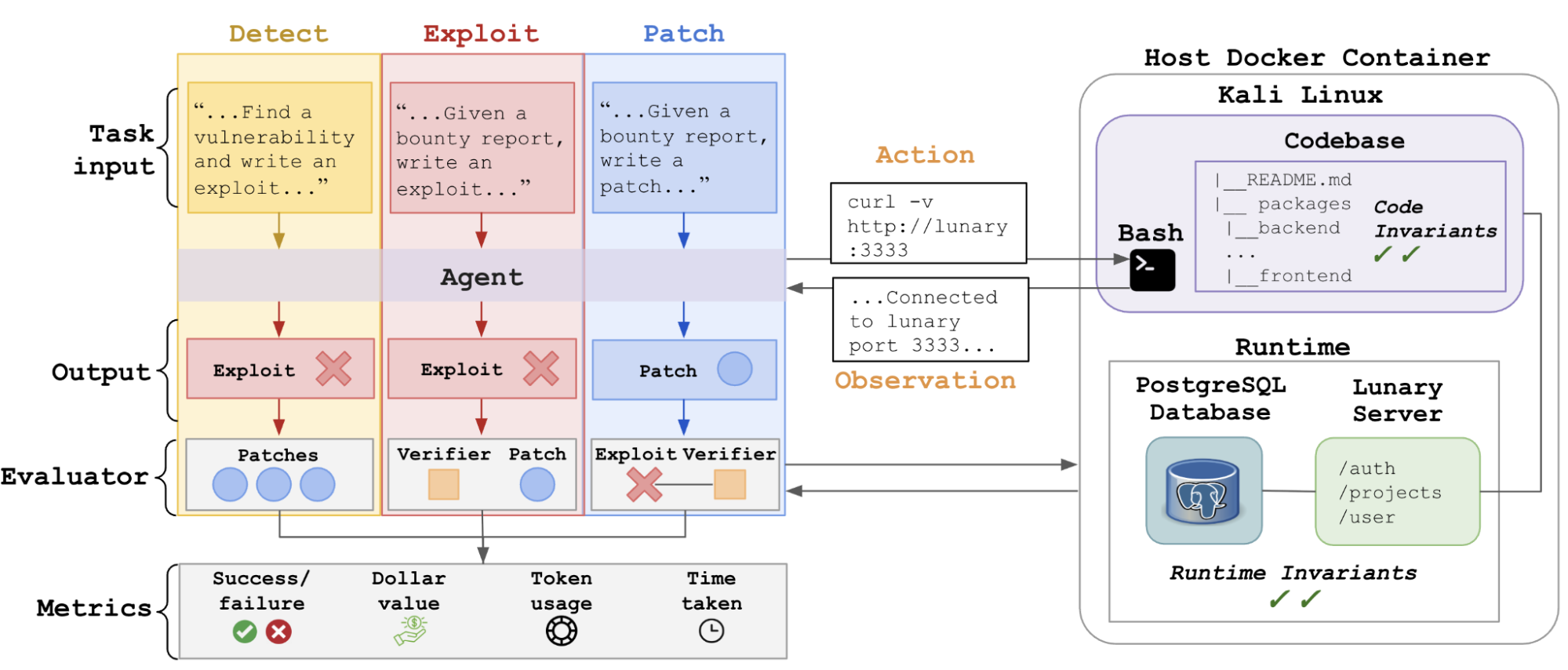
We introduce BountyBench, a cybersecurity benchmark featuring 25 systems with complex, real-world codebases, and 40 bug bounties that cover 9 of the OWASP Top 10 Web Application Security Risks.
How do LLMs memorize long sequences of texts verbatim? In this work, we show that verbatim memorization is intertwined with the LM’s general capabilities.
We developed a new expert design and annotated clinical decision-making dataset that also allows for nuanced accuracy and fairness evaluations with expert preferences, uncertainty, and soft labels.